Engagement Module
Next Gen AI Solution
Maintenance
Designing
Consultant
Industries
Zero Downtime Deployment in AWS with Tofu/Terraform and SAM
We still vividly recall those times when we had to put up a maintenance page and set a flag during application deployments. Most times we deployed our applications at odd hours, say midnight or during the downtime of users, which affected the experience of the developers negatively. Today though as clients, we don’t expect to have such interruptions in service.
Why Zero-Downtime Deployment
It’s now a norm in the current age of applications to have zero downtime deployments. We have reached the age of dispensing software in which there should be no or little inactivity and little latency. As clients, we have become more demanding. We believe that if an Application is so hard to use or does not function as it should, the application is not worth using and most likely will be ignored.
For these reasons today, we would like to share a few methods for achieving zero downtime deployments and for instilling confidence in your customers.
- Utilize the instance refresh feature for updating the Auto Scaling group instances (OpenTofu).
- Formation of Non-Changeable Infrastructure along with Changeable Software (Terraform + Ansible).
- Create Blue-Green implementation methods.
- Canary Deployments (Difficult Deployment with Serverless Applications).
Our perspective is to not build applications that can be termed as “unreliable” instead we choose to stay “cloud-native”.
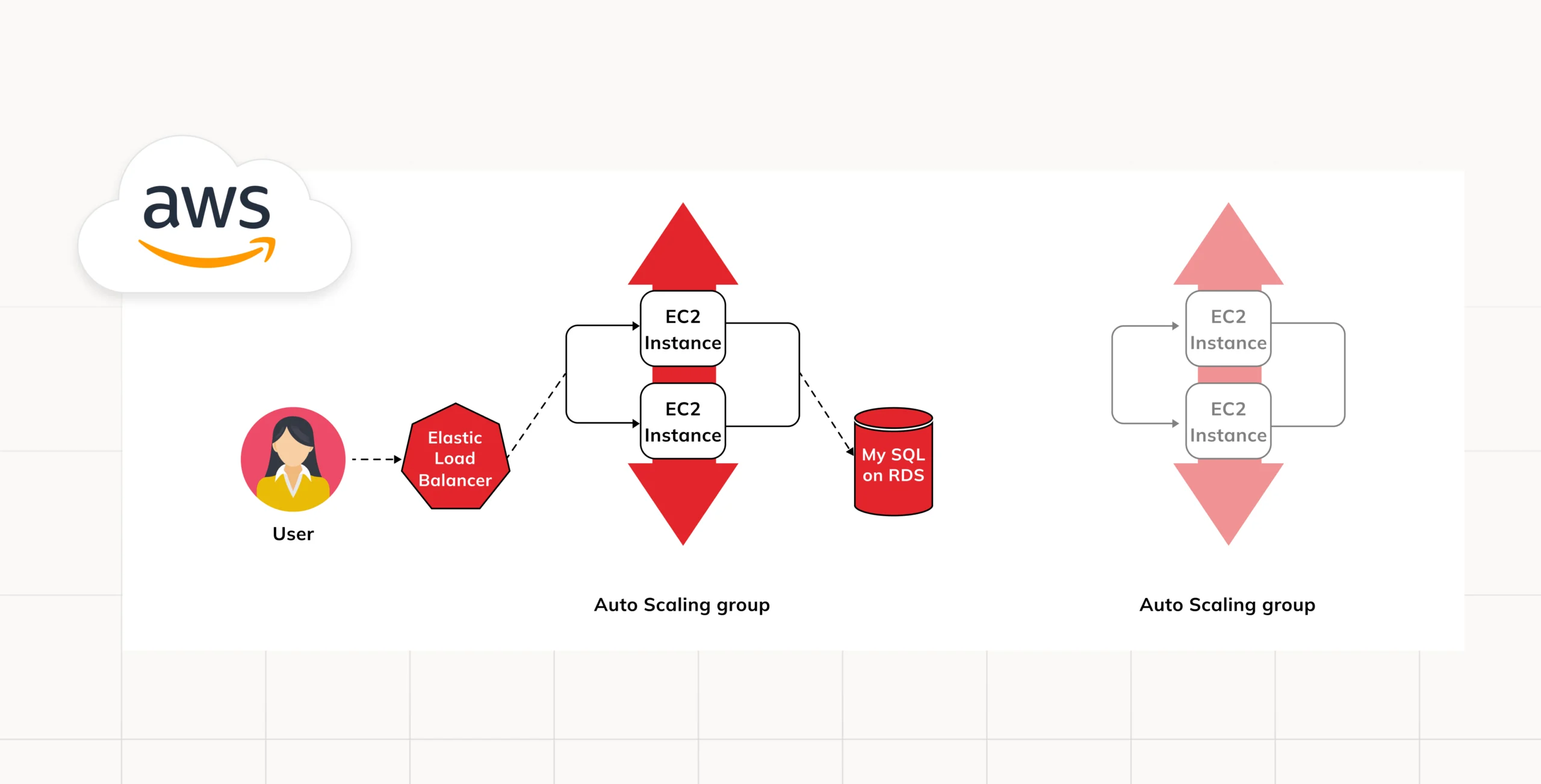
Use an Instance Refresh to Update Instances in an Auto Scaling Group (OpenTofu)
In this case, OpenTofu is the case in point. We would like to inform you of the benefits of using open-source software – it is very good and you get to use the work of other great people and enhance their work thanks to several resources. We have so much to gain from such endeavours. That is also a case why this particular code is a mixture of lots of different and ideas and is accessible for everyone willing to use and modify it.
We need to define three important attributes: min_elb_capacity, lifecycle, and instance_refresh. These attributes will serve the following purposes:
min_elb_capacity: This attribute ensures that the deployment is considered complete only after at least some instances have passed health checks.
lifecycle: This attribute helps prevent the deletion of previous resources after the new ones have been created.
instance_refresh: This attribute defines a strategy for rolling out changes to the Auto Scaling Group (ASG).
resource "aws_autoscaling_group" "zdd" {
name = "${var.cluster_name}-${aws_launch_template.zdd.name}"
vpc_zone_identifier = var.subnets
target_group_arns = [aws_lb_target_group.asg.arn]
health_check_type = "ELB"
min_elb_capacity = var.min_size
min_size = var.min_size
max_size = var.max_size
lifecycle {
create_before_destroy = true
}
# Use instance refresh to roll out changes to the ASG
instance_refresh {
strategy = "Rolling"
preferences {
min_healthy_percentage = 50
}
}
launch_template {
id = aws_launch_template.zdd.id
version = "$Latest"
}
tag {
key = "Name"
value = var.cluster_name
propagate_at_launch = true
}
}
The result is an API that returns data reliably without becoming unavailable.
In this example, we rely on immutable infrastructure, so we need to pack and create a new AMI whenever there is a change.
packer build sample-app.pkr.hcl
tofu apply
Immutable infrastructure + Mutable Applications (Terraform + Ansible)
Provisioning tools like Terraform or CloudFormation allow one to do everything. However, at times it is wise to combine them with the likes of Ansible, A configuration management tool, which lends itself well to sourcing of software on servers thereby facilitating seamless deployment. Zero downtime deployment is possible with the use of Ansible as it is meant for installing and managing software on servers.
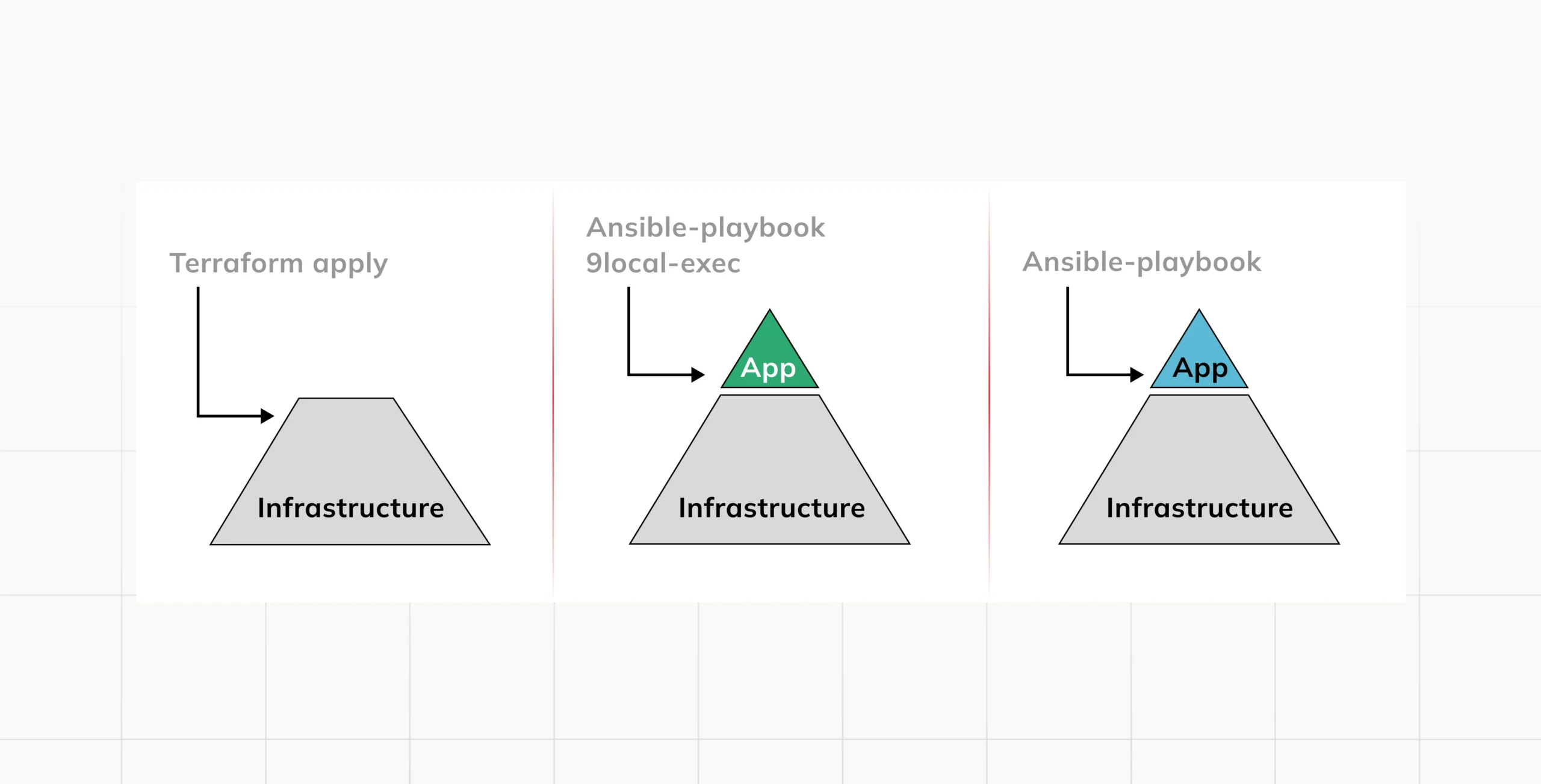
We can serve our application with Nginx
- name: Install Nginx
hosts: all
become: true
tasks:
- name: Install Nginx
apt:
name: nginx
state: present
- name: Add index page
template:
src: index.html
dest: /var/www/html/index.html
- name: Start Nginx
service:
name: nginx
state: started
The result is an application that can be easily updated with an Ansible command, leading to zero downtime.
Blue/Green Deployments
Essentially, the concept implies operating multiple environments running several versions of the same application. You may choose to implement all changes at once or a fraction of them in phases. The blue environment occupies the live production space while the green one is a test bed with the new version of the application being tested or validated. Once the green pit becomes stable, traffic is cut over to it. In case of issues, it is possible to fail by moving the traffic back to the blue pit.
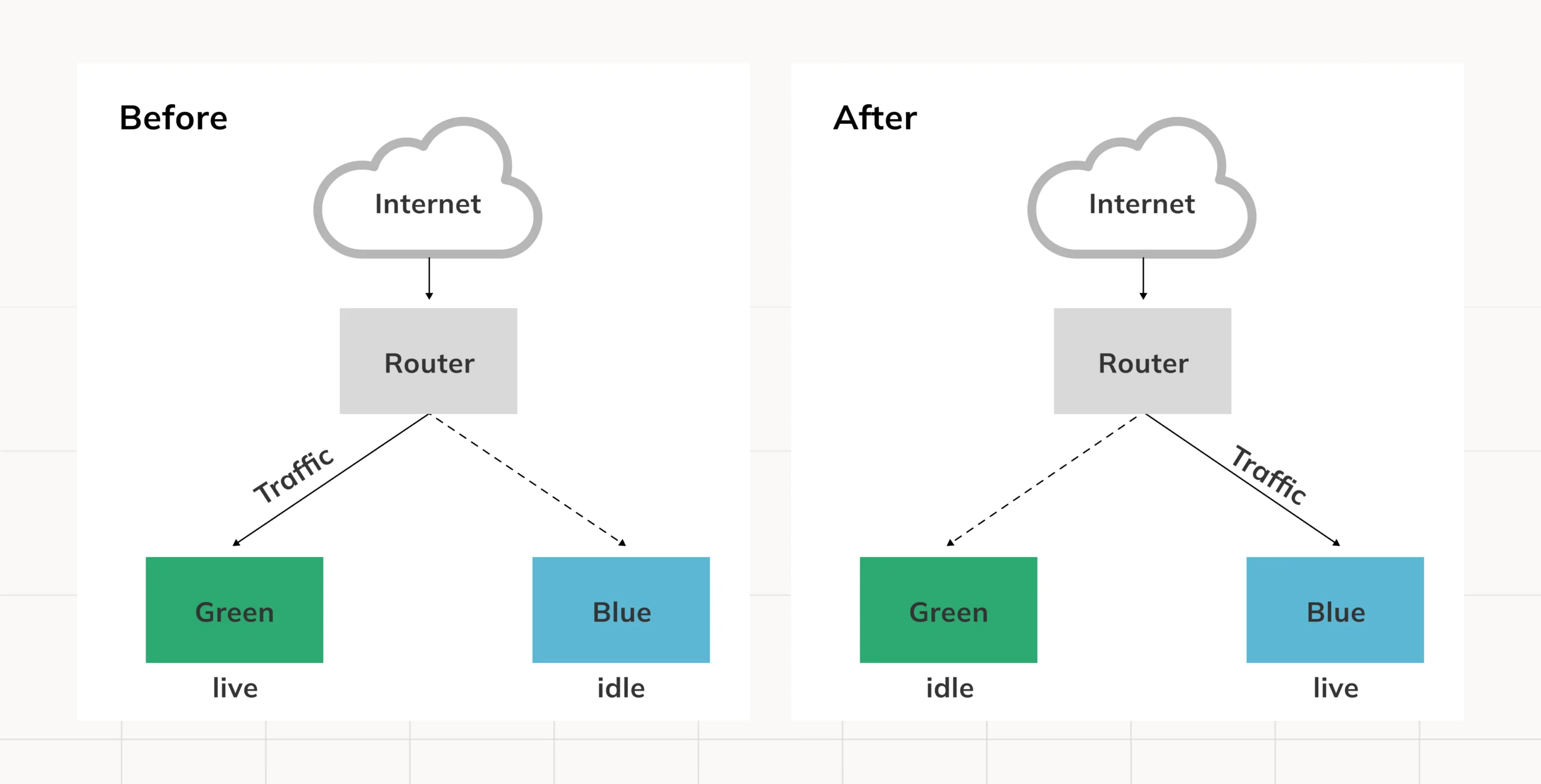
The community is one of the greatest aspects of AWS and Terraform. As one can see, the public modules can be used for building the application. However, in this scenario, the system enables toggle changing between the modes using a flag. Each time an iteration of the application is made, a new version of the application is available for future traffic while the previous live version continues serving traffic until it is confirmed that the facility does not have any problems and the switch is affected.
provider "aws" {
region = "us-east-2"
}
variable "production" {
default = "green"
}
module "base" {
source = "terraform-in-action/aws/bluegreen//modules/base"
production = var.production
}
module "green" {
source = "terraform-in-action/aws/bluegreen//modules/autoscaling"
app_version = "v1.0"
label = "green"
base = module.base
}
module "blue" {
source = "terraform-in-action/aws/bluegreen//modules/autoscaling"
app_version = "v2.0"
label = "blue"
base = module.base
}
output "lb_dns_name" {
value = module.base.lb_dns_name
}
Canary Deployments (Deploying Serverless Applications Gradually)
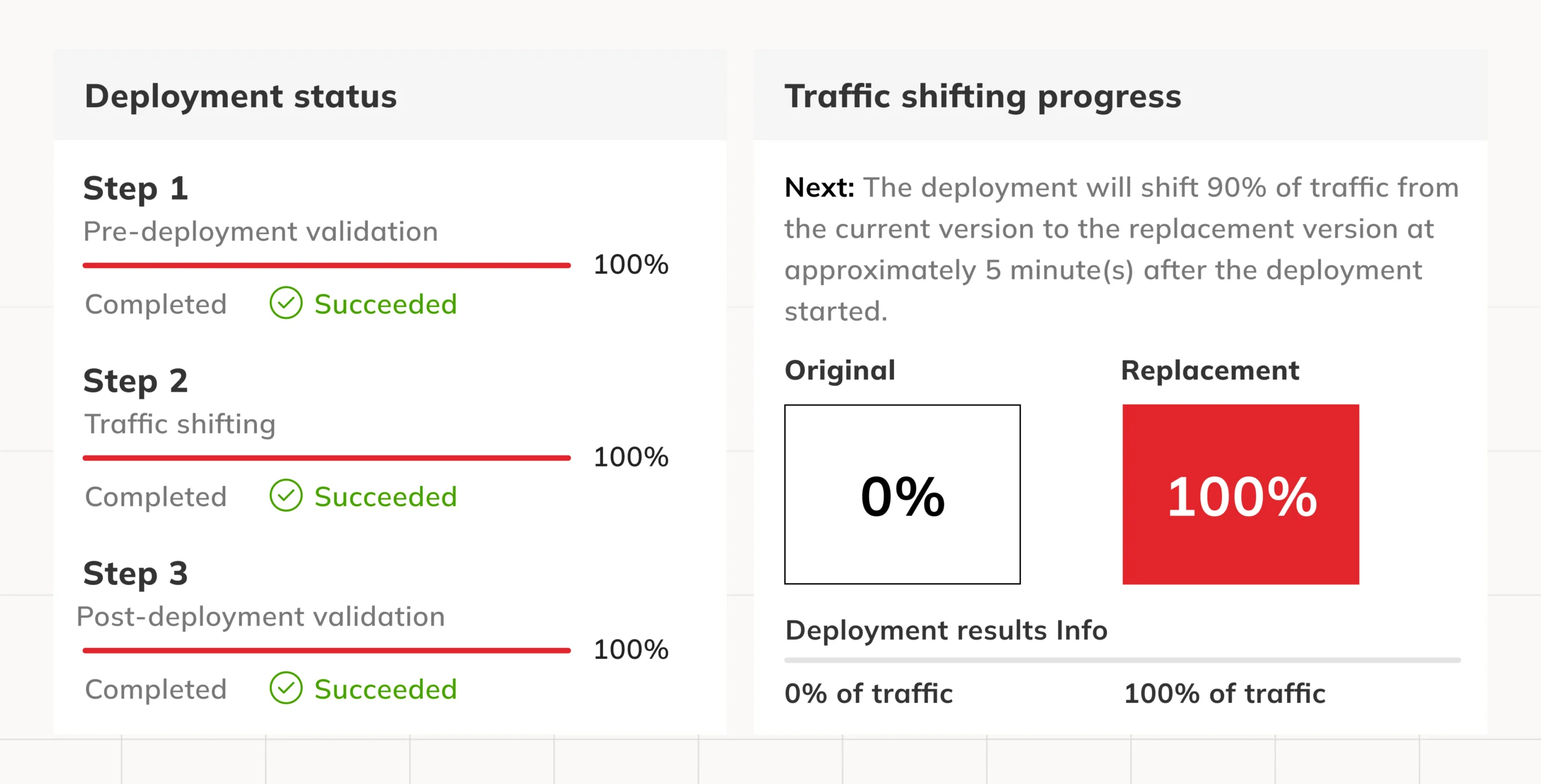
The method is essentially to roll out the software gradually to a small group of individuals first. This way, we get to know if everything is ok and progressively increase the number of users who can access the latest application version. When any issue arises, we can swiftly revert to the older version by turning down the volume of traffic on a new version to none.
For instance, with SAM out of the box, you can use CloudWatch alarms to validate traffic and manage rollbacks. This is quite useful when the changes in the logic might be more expensive than the others.
Conclusion
- Zero-downtime deployments are paramount in establishing confidence in cloud applications owing to their still-evolving nature.
- Such capability is part and parcel of the provided features for safely deploying infrastructure with SAM.
- DevOps practices can be enhanced, with less disruption of existing deployments, by the combined use of Ansible and Terraform whereby the application is enhanced instead of completely redoing it.
- Usually, it is found that immutable infrastructure is preferable since there will be consistent deployment of the same configuration as opposed to a server where several modifications have been made possibly resulting in other configurations.
- Likewise, immutable infrastructure has its cons among them being the need to build an image from the server template that is to be changed and then deploy it.
- OpenTofu is a fantastic tool for provisioning infrastructure. we have not used it in the past, however, I have a feeling the community is doing a stellar job around it and that all upcoming releases will add more and more functionality that Terraform currently lacks.
In conclusion, we would recommend meeting with Braincuber who is quite knowledgeable on this subject for more tips on mastering Zero Downtime Deployment using Terraform, Tofu and AWS SAM.